Hieroglyphic: visualizing an intermediate language for software development
I did a solo hack week project at GitHub and wrote about it on Team, GitHub’s internal forum, at the time. The following is a cross-post.
This morning I had the opportunity to demo my hack week project: Hieroglyphic. Check out the demo and read the following write-up to learn more about its potential and how it could tie into the work of the Semantic Code team.

Product description
Hieroglyphic provides a richer, more expressive and more visual way to understand, learn and communicate about code. It lets users draw, diagram, mark-up and write on code. It’s meant to give developers, designers, learners and educators more degrees of freedom when reasoning about software.
Just like photoshop has layers—we should be able to have “layers” for our code files. This will allow us capture more data across the software development lifecycle illustrating how we think through problems and build programs.
Problems to solve
Presently, Atom and other editors support a text-only workflow. Various programming languages have comments, which let us annotate source code with explanations and additional information that make it easier for humans to reason about the program. Comments are great for succinctly communicating about code in natural language. However, textual representation can be limiting when trying to learn, assimilate knowledge or communicate complex, non-linear connections that require our thoughts to expand in several directions. Code is often inherently non-linear and requires us to hold multiple connections in our heads. Textual comments constrain our ability to express richer spatial information that represents connections in code.
We imagine coding to be a linear process that looks like this:

…but it often looks more like this:
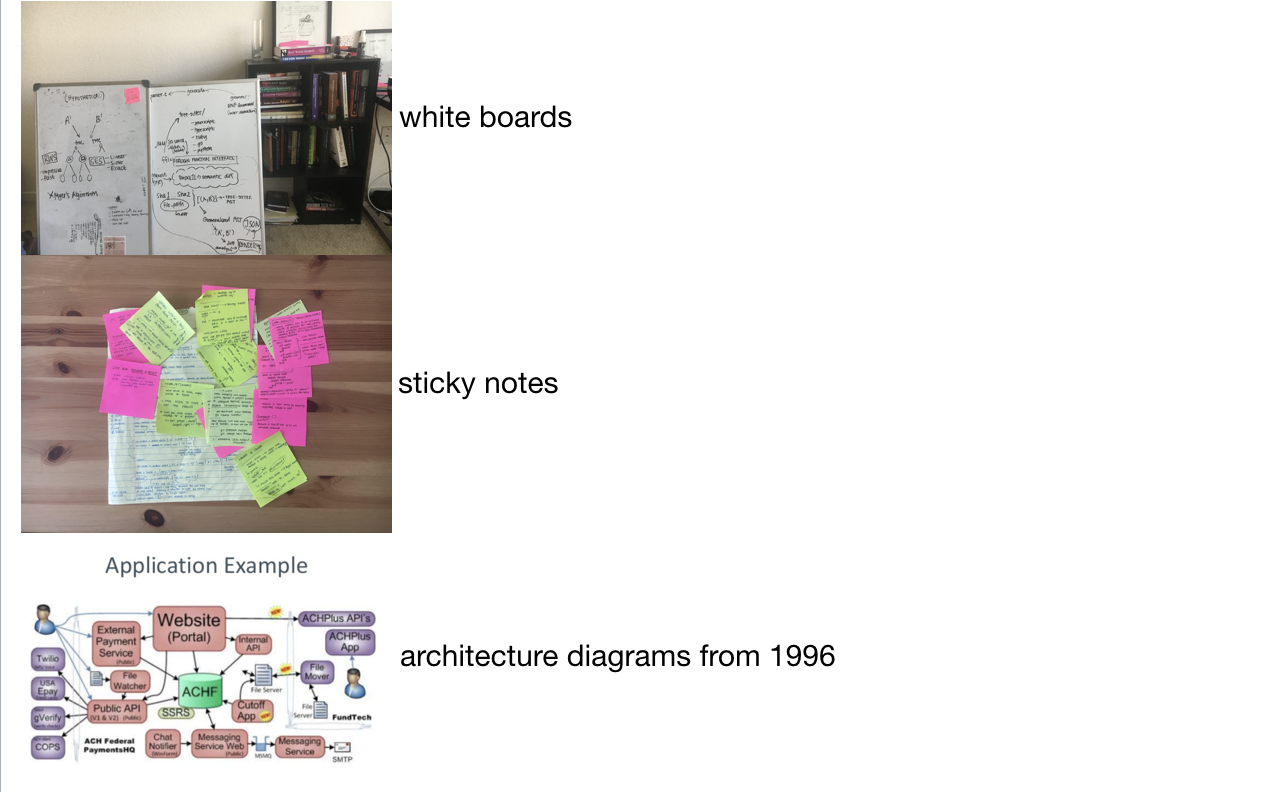
Current “state of the art”
The tools used for code-related visual information are messy and disaggregated from the code files they are meant to describe. Sharing a personal example, I am engineer on the Semantic Code team. Like most developers, I’m constantly learning—whether that means learning new languages, getting acquainted with different DSLs, familiarizing myself with entirely new code bases, systems and then integrating that knowledge into the work that I do; learning is part of my job. However, these are messy tools I’m currently subjected to:


GitHub is uniquely positioned to solve these problems and fill this gap.
Storing visual data
We could store a URL + span + SHA, which we could use to figure out whether or not the annotation is still relevant. This would be similar to how we decide whether comments should be folded because the code they were attached to changed or not in PRs. We could attach them to tree nodes and we could recover the associations between them and tree nodes from spans.
In the ASTs we generate, we have information about the location of each node in the tree, as well as its line and column. So if we know what line, column and node you’ve attached your annotation to, we could recover that association. If that particular line was later deleted, the annotation associated with it would also be deleted.
We could also allow selections to be node-specific, similar to being able to select granularity levels in a web inspector in your browser.
Semantic code and our mission
Our mission is to help developers make, improve and understand code. We have acknowledged that GitHub has one of the largest and richest software data sets in the world and that we can leverage what we know about source code. However, if we started capturing more of the software lifecycle, it would give us more insight to build tooling that is thoughtful and relevant to the pain points experienced by developers.
Why GitHub should do this
GitHub’s strength lies in its code-related data. The more places we allow users to contribute, the more we absorb all possible data from software lifecycle. A lot of ancillary work is done to build software, but it remains undocumented. Not only do visual annotations make code much more expressive, but they also provide us with the ability to understand how users learn and integrate knowledge into their workflows. When discussing how effective a language or tool is, we tend to place our focus on speaking in terms of technical correctness instead of user-friendliness. The pedagogical and psychological study of how human thought interacts with the language or technology is extremely nascent, poorly understood field. This area of study also has the potential to make computing more accessible for a wider group of people. In fact, one of our OKRs is to “democratize software”. To do so, we must acknowledge that there is a multiplicity of learning styles and learners, and we must accommodate.
The struggle is real: my philosophical soapbox
Making development “easy” should not be conflated with “dumbing things down”. GitHub’s intent should not be to create code assistants that replace critical thinking skills, or to promote bite-sized, convenient forms of “edutainment” that stifle true, deep learning. The purpose is not to eliminate the struggle, but to displace it. Struggling is an inherent and crucial part of learning. But instead of struggling to keeping track of sticky-notes or remembering what page of a notebook an important idea is written on, I’d like to spend my time focused on struggling to solve a problem, understand Haskell or category theory. I want to reinforce concepts meaningfully. I want my struggle to be productive.
Throughout the history of computer science, we’ve seen abstraction on top of abstraction. As we develop new computing languages and techniques, the complexity we’re grappling with increases, even if the highest level layer looks more approachable or intuitive. This means that we need better tools that allow us to understand what’s under the hood and make sense of the complexity we’re generating. Creating tools that make things “easy” doesn’t mean we’re creating code assistants that replace our critical thinking skills. Rather, we need tools that allow us to build deep, scientific and mathematical intuition for the problems we are studying and solving so we can support better software engineers and better computer scientists.

“The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.” — Edsger W. Dijkstra
Platform approach
GitHub is well positioned to drive this forward. This should be an extension available for any text editor and on GitHub.com. If we open this up as an API for annotations, people will come and build great things.